
ReKisstory creator
Wikidata or Wikipedia?
5 min to read
ReKisstory uses Wikidata as the data source, although we also provide links to Wikipedia. Most people know Wikipedia, but what about Wikidata? It is still unknown to many. The names are also confusing, right? So, let me explain the difference in this article.
To be Wikidata or Wikipedia, that is the question
According to a website ranking, in July 2024, Wikipedia is the 7th most visited site on the web. 23 billion page views per month. This is big. It is a wonderful source of free information for everybody. It is easy to find articles and there is a lot of information available in many languages. In the past, we could only do it if we buy a thick book like Britanica. They are good read inded. But, something is missing for us; if we would like to pinpoint specific information inside millions of articles, it is not easy. In addition, if we would like to count how many articles contain the same information, like, how many films were created in 2020, or how many rivers are longer than 100 km, it is not easy. Why?
Because it is not a database. You can search full-text in Wikipedia, but it is different from what you search products in Amazon or hotels in Bookings.com. The reason is simple. The data is not structured. In other words, Wikipedia is just a a lot of texts (with minimal data structure), while Amazon database has data structure like price, name and size of product, and user ratings. By structure, we mean spreadsheets like Microsoft Excel, roughly speaking. In other words, a data table with columns and rows. So, what if there is a database version of Wikipedia? Very useful, hah? That is what Wikidata is all about.
Machines and Humans
What is missing was what we call "machine access". As AI is re-shaping our world, I bet you know what I am talking about. But, hang on. Wikidata is different from AI. Wikidata is a data source for AI (as well as Wikipedia), because it is free. For AI, the machine consumes massive amount of data like websites, social media, and Wikidata. In this way, it can find patterns in them. It will tell you what is likely to happen if you give a similar pattern as input.
AI is another paradigm, so let's leave it for now. Generally speaking, machines prefer structure, because it is easy to understand for them. Programming is a structure, right? Commands are a structure. So, if we have a structure, we can pinpoint an answer to our question. In Wikidata, we can ask the above-mentioned questions: how many films were created in 2020, or how many rivers are longer than 100 km. In contrast, if we would like to do the same with Google and Wikipedia search engines, it is normally two steps (or more). First, we have to find a web page by typing keywords. If we are very lucky, we find websites containing a list of films in 2020, or a Wiki describing the comparison of rivers. Then, you have to do another search in the website to find the answers. Sometimes you don't even get a straightforward answer. You may need to calculate by yourself the number of films or rivers from a list on the website. Redundant!
Nowadays, AI gives you answers to the questions, but they are guessing, based on the likelifood of the text patterns. There could be a hallucination. AI may give you 95% probable answer, which is good enough for many cases, but if you don't want any misakes (like online banking transactions, or residence registration), then it's not a good option. In Wikidata, the answer is probably more reliable, as it will not give you a probable answer, but a 100%-confident answer, as long as the data exists, and correctly described. I will leave you think which data you want to trust: the data AI uses and guesses, or the data Wikidata/Wikipedia describes and provides. Both are useful, but never perfect in my view. One important thing about Wikidata and Wikipedia is that they are created by humans (with a help of machine data processing). It is an advantage that humans create and control, but it is a disadvantage that humans make mistakes or abuse. But, as long as you like Wikipedia and Wikidata, we should appreciate the volunteers who create and maintain them. And, do not forget you can also contribute to improve: How to add/edit Wikipedia (video) and Wikidata (video).
Understood the conceptual difference, but what is the actual difference in terms of quantity and quality?
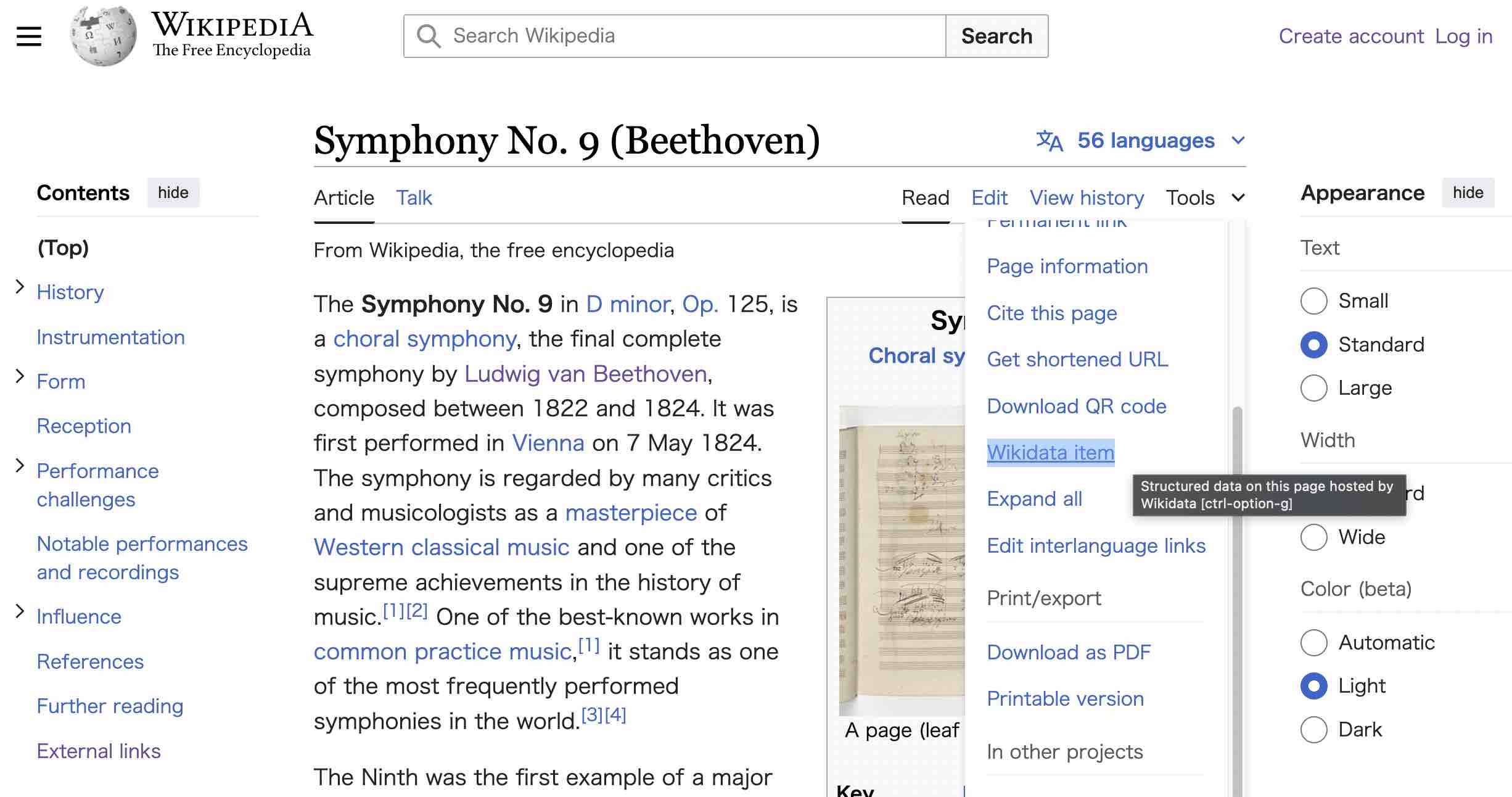
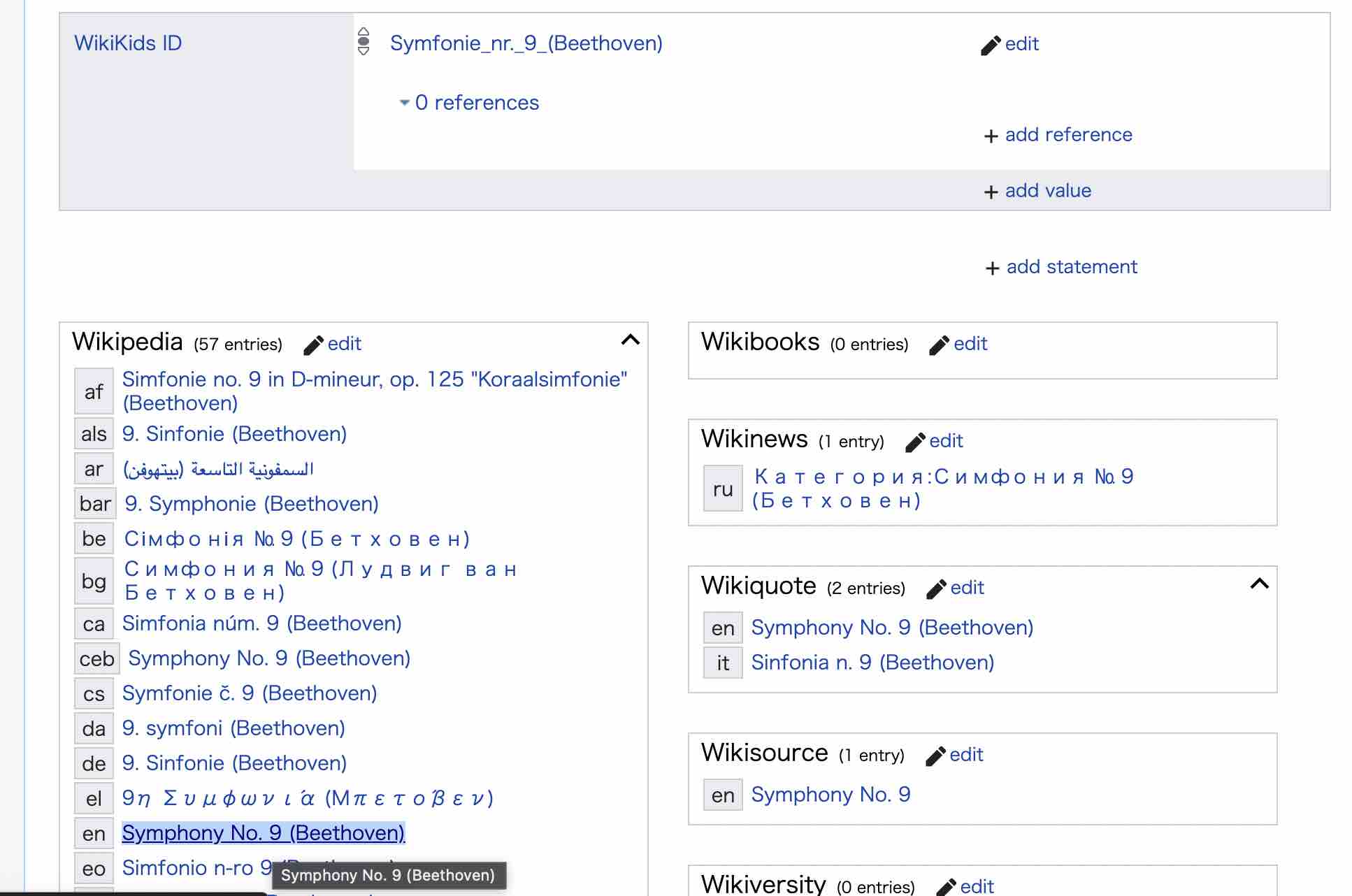
According to this latest statistics, Wikidata has 100 million items, including 10 million people, 3 million events, and 3 million places. Roughly speaking, the Wikidata items are the Wikipedia article entries. For example, Wikidata item Symphony No 9 of Beethoven (Q11989) has a link to Wikipedia articles in different languages. Likewise, Symphony No 9 of Beethoven in Wikipedia has a link to Wikidata item (although it is rather hidden at the moment). This is how normal users can go back and forth between Wikipedia and Wikidata. See also how to add/edit the link and more comprehensive read. I think Wikipedia is now based on information from the Wikidata items. So, we could say most articles in Wikipedia are included in Wikidata.
In the Wikidata community event, I asked how much overlap there is between Wikipedia and Wikidata. I was told that there is a tool called Duplicity to show the dynamically created statistics of matching between Wikipedia articles and Wikidata items. As you can see there are still bunches of gaps too.
ReKisstory is a powerful search engine for Wikipedia/Wikidata
Now, let's go back to ReKisstory. What is it? We could say that it is a search engine for Wikipedia and Wikidata. You may wonder if there is a Wikidata search engine already. Good question! Yes, there is. If you dare, you can try official search engines: a) full text search or complex search. How do you feel? If you have never used Wikidata, b) is impossible to use, right? (I would write about this search engine and technology in the blog later). It's designed for expert users like digital librarians. a) is easy, but it looks the same as Wikipedia search. You don't take advantage of database structure.
Here comes the saivor, ReKisstory. Wikidata is very complex and not for everybody at the moment. Our aim is to lower this barrier to make most of the power Wikidata for (relatively) novice users. So, enjoy exploring Wikidata with an easy interfaces and visualizations. All you have to do is to type and select from auto-suggest or dropdown menu, and we take care of the rest. If you want to know more about our tool, please visit about page.


"Eigentlich weiss man nur wenn man wenig weiss; mit dem Wissen wächst der Zweifel (We know accurately only when we know little; with knowledge doubt increases)"
Johann Wolfgang von Goethe
Source: Wikipedia